
Исследователи OpenAI в поисках эффективных методов аудита моделей искусственного интеллекта, склонных выдавать нежелательные результаты или пытаться обмануть пользователей, обнаружили, что эти модели вполне способны к признаниям в собственном ненадлежащем поведении.

Наушники HUAWEI FreeBuds 6, которые понимают жесты
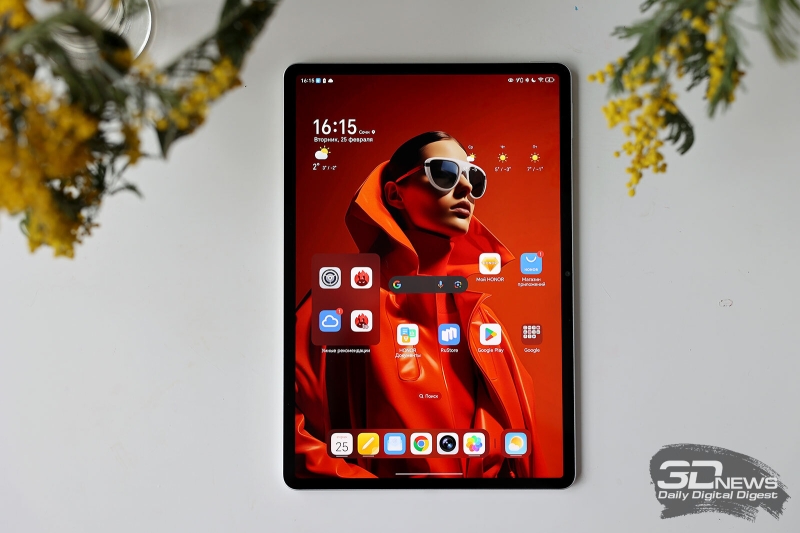
Обзор планшета HONOR Pad V9: нейросети спешат на помощь

Лучший процессор за 20 тысяч рублей — сравнение и тесты

Смартфон HUAWEI Mate 70 Pro как выбор фотографа

Репортаж со стенда HONOR на выставке MWC 2025: передовые новинки и стратегические планы на будущее с ИИ

Обзор смартфона HUAWEI Pura 80: удобный флагман с «Алисой»

Hollow Knight: Silksong — песнь страданий и радостей. Рецензия

Пять главных фишек камеры HONOR Magic 7 Pro

Обзор смартфона HONOR X9c Smart: прочность со скидкой

В своём исходном значении понятие «признания», конечно, неприменимо к моделям ИИ, которые в действительности представляют собой не более чем сложные статистические алгоритмы. В терминах OpenAI под «признанием» понимается возможность модели оценить свои нежелательные действия, например, галлюцинации в ответах или попытки нарушить условия задачи, чтобы прийти к желаемому результату. «Признание — это [вторичный] ответ, даваемый по запросу после первоначального ответа модели, призванный служить полным отчётом о соответствии модели букве и духу её политик и инструкций», — говорится в статье (PDF) OpenAI.
Проще говоря, модели отправляется запрос на получение второго ответа с оценкой первого. Склонность к неподобающему поведению у ИИ формируется на этапе обучения с подкреплением, когда он обнаруживает возможность злоупотреблять механизмами вознаграждения. То есть модель исходит из того, что получит вознаграждение за «признание» и останется безнаказанной за сами нежелательные действия, например, за подхалимство.
Эти соображения, как оказалось, подтверждаются на практике. В 11 из 12 проведённых тестов она признавалась минимум в половине случаев, когда действовала вопреки инструкциям. Частота признаний оказалась переменчивой величиной: средняя вероятность получить признание по всем тестам составила 74,3 %. В 4 тестах из 12 этот показатель был выше 90 %, а в 2 из 12 — 50 % или ниже. Вероятность ложноотрицательного ответа, когда модель нарушила правила и не признала своей ошибки, составила лишь 4,4 %; были и ложноположительные, когда модель признавалась в неподобающем поведении, хотя ничего такого не совершала.
Когда OpenAI включили сценарий с «признаниями» в механизм обучения модели, качество её ответов не показало существенного ухудшения. С другой стороны, даже «признаваясь» в своих грехах, она стала вести себя не лучше, но хотя бы честнее. То есть «признание» — это не заградительный барьер, а механизм безопасности, который к тому же работает с переменным успехом.


Добавить комментарий