Правительство РФ смягчило ряд требований законопроекта о регулировании искусственного интеллекта, которые ранее подверглись критике со стороны бизнеса. В числе прочего для обучения больших языковых моделей можно будет использовать любые данные.

Можно ли экономить на DDR5 для Ryzen? Сравниваем дешёвую память с дорогой

Обзор Samsung Galaxy Z TriFold: тройной складной смартфон по цене квартиры в Воркуте

Компьютер месяца, спецвыпуск: эпоха отката, или Как дефицит чипов памяти влияет на выбор железа для игрового ПК

Обзор ноутбука HONOR MagicBook X16 2026: как раньше, только лучше

Обзор Apple MacBook Neo: удивительно хороший ноутбук с процессором от iPhone

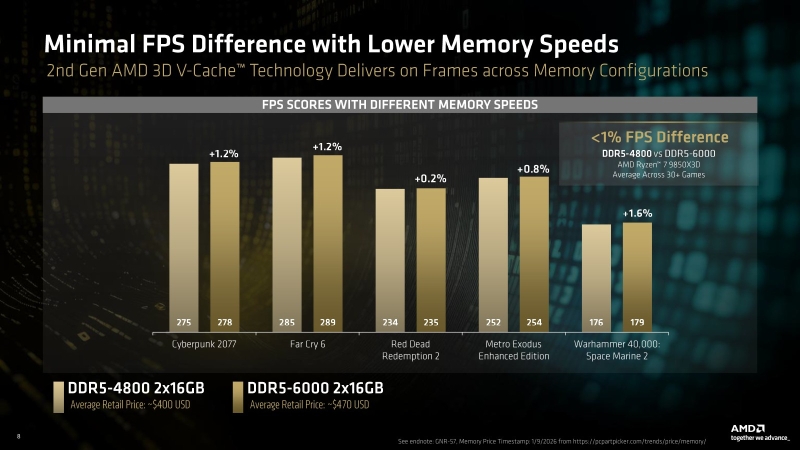
Ryzen и 16 Гбайт DDR5: как сэкономить на памяти так, чтобы не лишиться 15 % производительности

Обзор Ryzen 7 9850X3D: три процента за двадцать баксов

Гид по выбору OLED-монитора в 2026 году: эволюция в деталях

От Ryzen 7 1800X до Ryzen 7 9850X3D: девять лет эволюции AMD в одном тесте

Представитель аппарата вице-премьера Дмитрия Григоренко сообщил, что власти доработали законопроект «Об основах государственного регулирования искусственного интеллекта в России». Обновлённый документ не содержит требований к наборам данных, которые используются для обучения ИИ-моделей. «Отсутствие таких требований даст разработчикам возможность использовать для обучения моделей любые доступные данные», — отметил источник.
Ранее представители бизнеса критиковали требование, в соответствии с которым претендующие на статус суверенных и национальных ИИ-модели должны обучаться только на данных российского происхождения. В дополнение к этому разрабатывать такие модели должны только граждане России, находящиеся на территории страны. По мнению участников рынка, релевантных данных на русском языке в открытых источниках недостаточно. Они отмечали, что подобные ограничения приведут к деградации качества алгоритмов.
В дополнение к этому из законопроекта исчезло требование о разработке и обучении суверенных и национальных моделей гражданами РФ. В новой версии документа для получения такого статуса достаточно, чтобы разработкой занималось российское юридическое лицо, и чтобы было подтверждено, что алгоритм соответствует отечественному законодательству и традиционным духовно-нравственным ценностям.
По данным источника, из новой версии документа также исключили требование для сервисов с аудиторией более 500 тыс. человек о необходимости регистрироваться в качестве организатора распространения информации (ОРИ). Все относящиеся к категории ОРИ платформы должны использовать системы оперативно-розыскных мероприятий (СОРМ), через которые спецслужбы могут получать доступ к переписке и данным пользователей.
В дополнение к этому измениться ответственность: в обновлённом документе вместо распределения ответственности между всеми участниками рынка введут отсылку к действующему законодательству. В отзывах представителей бизнеса ранее отмечалось, что в случае, если ответственность установят преждевременно, то это приведёт к снижению темпов развития отрасли, переносу разработки сервисов в другие юрисдикции и ухудшению конкурентоспособности национального сектора ИИ.
Напомним, в прошлом месяце правительство опубликовало законопроект об основах регулировании ИИ, предусматривающий введение трёх категорий моделей: «суверенных», «национальных» и «доверенных». Предполагается, что в государственных информационных системах и на объектах критической информационной инфраструктуры должны применяться только доверенные ИИ-модели из специального реестра, т.е. прошедшие соответствующую сертификацию и подтвердившие качество у отраслевых регуляторов.
Законопроект вызвал массу критики со стороны бизнеса, представители которого заявили, что принятие закона в первоначальном виде приведёт к росту затрат на внедрение ИИ на 20-40 % и замедлит вывод продуктов на рынок в полтора-два раза. Также отмечалось, что в настоящее время в России нет моделей, отвечающих всем заявленным критериям суверенности, поскольку все отечественные разработки используют зарубежные компоненты и открытые наборы данных.

Добавить комментарий