
Дальнейшее совершенствование ИИ-систем, которое обеспечит переход от ChatGPT к использованию человекоподобных роботов, зависит от качества данных, которые предоставляются этим системам для обучения, пишет ресурс Fortune.

Обзор Apple MacBook Neo: удивительно хороший ноутбук с процессором от iPhone

Обзор Samsung Galaxy Z TriFold: тройной складной смартфон по цене квартиры в Воркуте

Гид по выбору OLED-монитора в 2026 году: эволюция в деталях
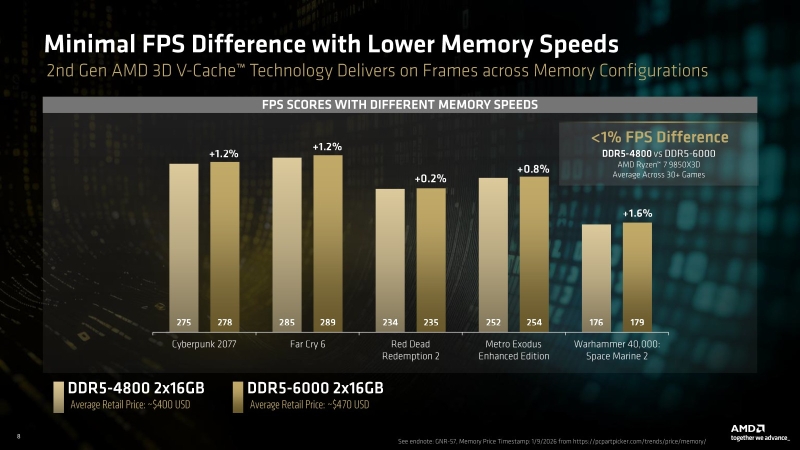
Можно ли экономить на DDR5 для Ryzen? Сравниваем дешёвую память с дорогой

Компьютер месяца, спецвыпуск: эпоха отката, или Как дефицит чипов памяти влияет на выбор железа для игрового ПК

Обзор ноутбука HONOR MagicBook X16 2026: как раньше, только лучше

От Ryzen 7 1800X до Ryzen 7 9850X3D: девять лет эволюции AMD в одном тесте

Ryzen и 16 Гбайт DDR5: как сэкономить на памяти так, чтобы не лишиться 15 % производительности

Обзор Ryzen 7 9850X3D: три процента за двадцать баксов

Ресурс отметил, что отрасль находится на пороге следующего рубежа ИИ — физического ИИ и моделей окружающего мира — систем, которые будут учиться и в конечном итоге работать в физическом мире. Для того чтобы они получили когнитивные способности, необходимые для навигации по дорогам, складывания белья или оказания помощи при сложных медицинских операциях, им требуются не просто данные, которые можно загрузить. Их обучение требует богатых и многогранных данных. И если исследователи не смогут остановить избыток ненужных данных — данных, которые не способствуют развитию модели, — весь потенциал физического ИИ и моделей окружающего мира может никогда не раскрыться в полной мере.
Проблема заключается в том, что для создания новых, более совершенных ИИ-моделей требуется всё больше данных. На волне ажиотажа вокруг ИИ возникло множество ИИ-стартапов, таких, как Scale AI, Surge AI и Mercor, испытывающих ненасытную потребность в данных. Однако удовлетворение этой потребности привело к появлению огромного количества ненужных данных, которые на самом деле никак не способствуют развитию моделей ИИ, отметил Fortune.
Обучение моделей пониманию сложного многомерного мира требует значительно больше данных — данных, которые также очень трудно получить. Инженеры по машинному обучению прибегают к моделированию данных, используя виртуальные реконструкции реальных сценариев для создания данных, которые будут использоваться для обучения роботов и беспилотных автомобилей.
Использование некачественных данных при обучении ИИ-моделей может привести к непредсказуемым результатам. Как утверждает ресурс Fortune, OpenAI прекратила поддержку видеоприложения Sora из-за проблемы некачественных данных, поскольку её модель мира не обладала достаточным пониманием физики, что затрудняло реалистичные прогнозы.
Для дальнейшего продвижения ИИ-специалистам, занимающимся машинным обучением, необходимы инструменты и технологии для удаления ненужных данных, которые анализируют, очищают, нормализуют и корректируют обучающие данные. Для достижения успеха в обучении потребуется извлечение ценных выводов и их отделение от ненужных данных.
Теперь ограничивающим фактором стала нехватка качественных данных. Компании, которые первыми поймут это, создадут ИИ-системы, которые действительно будут работать, пишет Fortune.

Добавить комментарий