
Три языковые ИИ-модели — ChatGPT-5, Gemini 2.5 и Claude 4.5 — по-разному оценили, каким профессиям больше всего угрожает искусственный интеллект. Эти расхождения ставят под сомнение надёжность так называемых индексов подверженности ИИ — числовых оценок того, насколько та или иная профессия рискует быть автоматизированной. Именно на такие индексы опираются политики и работодатели, принимая важные решения.

Компьютер месяца — май 2026 года
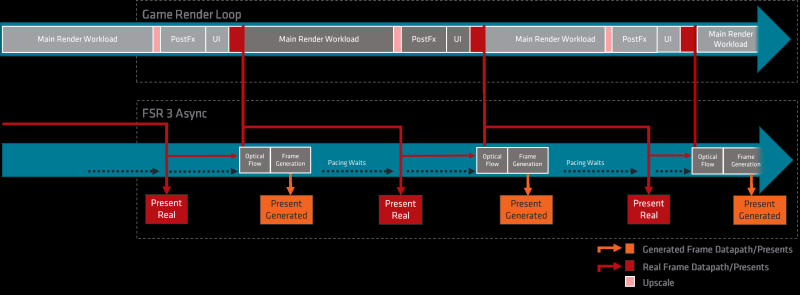
Больше кадров — больше лага: тестирование латентности с генерацией кадров DLSS и FSR

Обзор Apple MacBook Neo: удивительно хороший ноутбук с процессором от iPhone
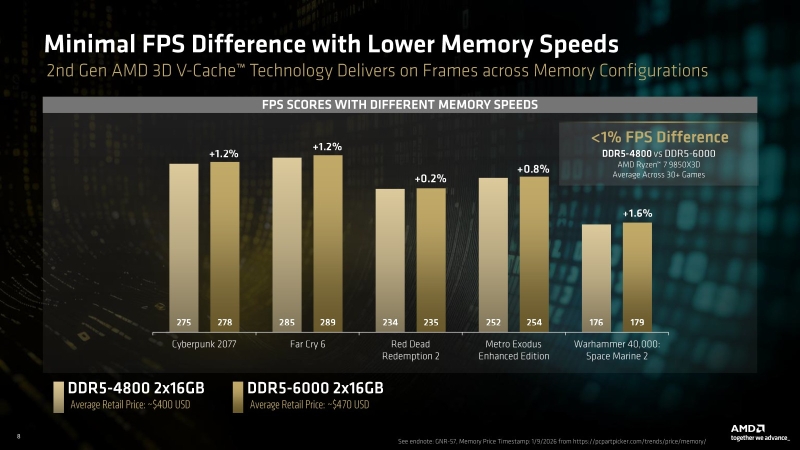
Можно ли экономить на DDR5 для Ryzen? Сравниваем дешёвую память с дорогой

От Ryzen 7 1800X до Ryzen 7 9850X3D: девять лет эволюции AMD в одном тесте

К такому выводу пришли экономисты Мишель Инь (Michelle Yin) и Хоа Ву (Hoa Vu) из Северо-Западного университета (NU), а также Клаудия Персико (Claudia Persico) из Американского университета (AU). В своей предварительной научной работе исследователи попросили три ИИ-модели оценить, какие профессии наиболее уязвимы перед ИИ, и часто получали разные ответы. Claude присвоил профессии бухгалтера высокую степень уязвимости, тогда как Gemini оценил её заметно ниже. Модели разошлись и в оценке уязвимости рекламных менеджеров, и в оценке руководителей высшего звена. ChatGPT и Gemini оказались наиболее согласованными между собой, но и они расходились примерно в четверти случаев.
Часть расхождений объясняется различиями между самими ИИ-моделями, однако экономисты обнаружили и другой фактор: на оценки влияло то, какие специалисты уже пользуются ИИ. Первые пользователи — например, финансовые аналитики — активно работают с нейросетями и тем самым генерируют больше данных, на которых обучаются будущие ИИ-модели. Это, в свою очередь, отражается на том, как модели оценивают такие профессии.
Индексы подверженности ИИ строят тремя способами: вручную, когда эксперты оценивают, насколько ИИ ускоряет выполнение тех или иных рабочих задач; с помощью опросов сотрудников, пользующихся ИИ-платформами; или с помощью самих больших языковых моделей (LLM). Ручные оценки могут быть весьма субъективными, а опросы отражают мнение пользователей лишь одной платформы и не обязательно представляют рынок труда в целом. Тем не менее эти индексы широко используются в аналитических записках, консалтинговых отчётах и докладах, подготовленных для обоснования политических решений.
Расхождения между разными версиями быстро развивающейся технологии сами по себе неудивительны. К тому же пока неясно, оценивают ли ИИ-модели подверженность автоматизации хуже или лучше, чем другие методы. Но проблема, по словам авторов исследования, в том, что некоторые политики и работодатели могут принимать такие оценки за чистую монету.
Для начала экономисты считают, что исследователям следует опираться на ответы сразу нескольких ИИ-моделей, а не одной, и прямо указывать на неопределённость результатов. В конечном счёте, по их мнению, более точные ответы могут дать опросы о том, как ИИ реально внедряется в экономику и для каких задач применяется. «Лично я не стала бы полагаться на один-единственный показатель, чтобы решать: „Мне надо сменить работу“ или „Моему ребёнку надо сменить специальность“», — сказала Инь.

Добавить комментарий