
Есть ли какая-то цель у жизни в целом, и в частности у жизни разумной, — вопрос не столько даже философский, сколько, наверное, религиозный. Вместе с тем любое живое существо на тактическом, если можно так выразиться, уровне непрерывно ставит перед собой — пусть и не всегда до конца осознанно — те или иные цели: поступить именно в этот вуз, догнать именно эту антилопу, прикрепить к своему панцирю именно эту актинию. Да, формально тактическое целеполагание может выглядеть тривиальным: когда вуз выбирают поближе к дому, антилопу — самую слабую (уже по факту начала погони подметив, какая отстаёт сильнее прочих), актинию — так и вовсе первую попавшуюся. Но ведь и путь к самой на вид неприступной, отдалённой вершине представляет собой, по сути, цепь достижений взаимосвязанных тактических целей, так что обучить искусственный интеллект если не «осознанному», то хотя бы «тактически обоснованному» несложному действию значит в каком-то смысле сделать шаг навстречу пресловутому «сильному ИИ». Который уже, хочется надеяться, будет именно в человеческом понимании этого слова самостоятельно ставить перед собой задачи — а после отыскивать способы их решения. Не факт, что человечеству это не выйдет в итоге боком (сколько фантастики написано на эту тему, и не перечесть), но пока сильный ИИ продолжает оставаться не самой достижимой целью.
Изучающие поведение людей исследователи давно установили на практике, что деятельность с чётким целеполаганием — даже настолько банальная, как пешая прогулка к хорошо видимому ориентиру — гораздо эффективнее простого вышагивания в указанном направлении. Эффективнее в чисто физическом смысле: участники эксперимента, которые сосредоточивались на достижении указанной им точки маршрута, ни на минуту не выпуская её из вида, в среднем двигались быстрее и уставали меньше, чем представители контрольной группы, которым говорили просто «идите, пока вас не остановят». Как и биологическому существу, генеративной модели далеко не всегда имеет смысл ставить перед собой «осознанные» цели — как не делает этого, к примеру, взрослый человек, подносящий во время еды ложку ко рту (а вот только обучающийся есть самостоятельно ребёнок, наоборот, активно целеполагает в ходе каждого такого действия). Но у goal-driven AI есть своя важная прикладная область — и развивают такого рода системы в последние годы особенно активно.

⇡#Одна седьмая
Эксперты американского Института проектного управления (Project Management Institute, PMI) выделяют всего семь моделей применения ИИ, к которым — точнее, к различным сочетаниям которых, — сводятся сотни тысяч, если уже не миллионы практических реализаций этой новомодной технологии. Речь идёт о:
- гиперперсонализации (когда, скажем, буквально для каждого клиента в зависимости от его личного профиля — это может быть история покупок, медицинская карта, хроника участия в биржевых торгах и проч. — умная система формулирует оптимальное именно для него предложение),
- предиктивной аналитике и обосновании принятия управленческих решений (здесь на основании анализа длинных рядов предшествующих событий системами машинного обучения делаются аргументированные прогнозы о дальнейшем развитии ситуации),
- выявлении закономерностей и аномалий (похоже на предыдущую модель, но изучению подвергаются не временные ряды, а разрозненные данные по некой тематике, из которых извлекаются не обнаруженные людьми закономерности, причинно-следственные связи, а также, возможно, их статистически значимые нарушения, — а те, в свою очередь, могут либо свидетельствовать о неполноте массива данных, либо указывать на присутствие некоего неучтённого фактора),
- взаимодействии с людьми на естественных языках (привет, чат-боты!),
- распознавании (лиц на видео, связной речи в звуковом потоке, букв и слов в рукописном рецепте и т. п.),
- автономных системах (подразумеваются не только автономные грузовики или, скажем, складские погрузчики, но и программные боты, выполняющие определённый круг задач самостоятельно),
- и, наконец, о собственно целеполагающем, или целеустремлённом, ИИ (goal-driven AI — ЦИИ), который определяется как некий программный агент, способный отыскивать оптимальный путь решения поставленной перед ним задачи методом проб и ошибок: здесь принципиальное отличие от предыдущей модели как раз в допустимости промахов — никто ведь не будет с умилением наблюдать за самоуправляемым авто, раз за разом выезжающим на перекрёсток на красный, чтобы получить от оператора замечание: «Неверно, давай снова».
Важный момент: ЦИИ в принципе не может представлять собой однажды обученную (trained) и затем только применяемую (в режиме inference, с куда меньшими ресурсозатратами) нейросеть с зафиксированными весами: она всегда динамична и готова к непрерывной дотренировке. Система машинного обучения AlphaZero, созданная Google DeemMind с целью достичь превосходства над живыми игроками в классические шахматы, сёги (японскую их разновидность) и го, — удачный пример целеполагающего агента, добившегося бесспорного успеха задолго до наступления эры повсеместного распространения генеративного ИИ. Такой агент принципиально отличается от более ранних подходов к шахматному «снаряду», вроде нашумевшей в свой время разработки IBM под названием Deep Blue: та полагалась на обширнейшую базу, что включала по сути все возможные перемещения фигур на доске для огромного числа исходных позиций, и среди этого безбрежного моря потенциальных ходов эвристическими методами — на основе опыта биологических гроссмейстеров — стремилась всякий раз отыскать оптимальный.
Принцип действия AlphaZero иной: это глубокая нейросеть, обученная исходно не каким-то сложным гроссмейстерским приёмам, а самым базовым правилам совершения ходов. По завершении такого обучения AlphaZero просто начала играть (сперва в классические шахматы) сама с собой, попеременно принимая за той же самой доской сторону то чёрных, то белых; честно стремясь выиграть — по сути, сама у себя, притом не отступая от затверженных правил, — и так несколько миллионов раз. Процесс этот широко известен как «обучение с подкреплением» (reinforcement learning).
Существенно здесь то, что обучение с подкреплением ведётся иначе, чем другие популярные разновидности машинного обучения, — с учителем и без оного (supervised learning и unsupervised learning соответственно). Залогом успеха supervised learning служит обширный массив хорошо аннотированных — чаще всего человеком — данных, с которым система регулярно сверяется в ходе своей тренировки. Обучение без учителя, в свою очередь, подразумевает работу с неразмеченной информацией — для самостоятельного отыскания скрытых закономерностей и взаимосвязей. Обучение же с подкреплением ведётся, по сути, тем же образом, каким биологические нейросети обучаются в природе: методом проб и ошибок с применением поощрений и штрафов за каждое принятое решение. Здесь, конечно, есть риск, что система вместо поиска нерядовых путей честного выигрыша начнёт мухлевать, переиначивая правила в свою пользу или находя способ их обходить, — в этом уже замечены такие обучавшиеся с подкреплением актуальные модели, как OpenAI o1-preview и DeepSeek R1. С другой стороны, разве среди носителей биологического разума не встречаются шулера?
На первых порах AlphaZero перемещала фигуры по доске едва ли не хаотично (с соблюдением всех базовых правил, разумеется). Но достаточно быстро — благодаря удачной имплементации той самой функции поощрения, которую предварительно надо ещё определить и задать, — перестала допускать «зевки», «детские маты» и прочие банальные ошибки. Изменившиеся под действием функции поощрения веса на входах её перцептронов способствовали росту вероятности совершения менее тривиальных — если бы речь шла о человеке, уместно было бы сказать «более продуманных» — ходов; таких, которые в данной конкретной позиции оказывались бы именно для этого игрока (за чёрных или за белых) скорее выигрышными на перспективу. Компьютер, на котором проводилось обучение AlphaZero с подкреплением, был довольно мощным, а число возможных ходов в каждой позиции в любом случае ограничено, так что нет ничего странного в том, что начиная с какого-то момента ЦИИ принялся играть лучше практически любого гроссмейстера — не имея ни малейшего представления о дебютах, эндшпилях и прочей теоретической подоплёке игры. Интересно, кстати, что тренировка этой нейросети до приемлемого, на взгляд разработчиков, уровня по шахматам заняла около 9 часов, по сёги — 12 часов, а по го (где доска, отметим справедливости ради, гораздо крупнее) — 13 суток.
Команда DeepMind приводит восхищённые слова Ёсихару Хабу (Yoshiharu Habu), обладателя 9-го дана и единственного в истории игрока в сёги, что собрал все семь главных чемпионских титулов этой игры: «Некоторые ходы AlphaZero — например, перемещение короля («оосё», 王将) в центр доски — противоречат теории и, на взгляд человека, ставят компьютерного игрока в опасное положение. Но при этом тот, как ни странно, сохраняет контроль над доской, — и такой уникальный стиль открывает уже перед живыми игроками новые возможности». При этом, если специализированные на решении шахматных задач машины (та же Deep Blue) перебирают в поисках лучшего хода на каждом шаге десятки миллионов возможных перемещений фигур, AlphaZero ограничивается лишь десятками тысяч. Да, человеческий разум ещё совершеннее — гроссмейстер, опираясь на достижения теории и собственный опыт, кристаллизовавшийся в эвристику, прокручивает в голове «всего лишь» сотни возможных ходов. Но гроссмейстеры порой и проигрывают ЦИИ, тогда как тот, не скованный затверженными сборниками дебютов (как раз потому, что никаких сборников он не затверживал), привносит в игру свежие идеи и нетривиальные шаги, нередко ставящие в тупик биологических игроков.
⇡#По заслугам
Взятые напрямую из поведенческой психологии термины вроде «подкрепление», «награда», «штраф» могут вводить неспециалиста в заблуждение: в конце концов, программный целеполагающий ИИ-агент — даже не робот; его ни баночкой WD-40 не премировать, ни током в назидание за ошибку не шарахнуть. И поощрения, и штрафы для ЦИИ представлены попросту числами — положительными и отрицательными соответственно. Именно это числовое подкрепление, которым выражается оценка действий системы в той или иной ситуации, заменяет, к примеру, шаблон «истинных ответов», с которым сверяется обучающийся с учителем генеративный ИИ. Составление эффективной для данной конкретной модели таблицы подкреплений — настоящее искусство, поскольку тех может быть немало, в зависимости от поставленной оператором задачи. Например:
- простое фиксированное поощрение — за удачное выполнение некой рутинной процедуры (например, ведомый ЦИИ персонаж в компьютерной игре успешно перепрыгнул с одной движущейся платформы на другую — +1 очко),
- простой фиксированный штраф — за провал аналогичного рядового задания (робот, действующий в смоделированном виртуальном окружении, уронил взятый было с полки ящик — −5 очков),
- крупное (по модулю), но редко выдаваемое подкрепление (ЦИИ нашёл выход из особенно сложного лабиринта — +100; промахнулся мимо посадочной полосы и разбил самолёт в симуляторе — −500),
- привязанное ко времени подкрепление (очередной простой лабиринт пройден на 1 мс быстрее рекорда — +1; посылка доставлена в конечный пункт сложной сети при решении «задачи коммивояжёра» на 1 минуту медленнее прежнего — −1),
- накопительное поощрение, которое тем в итоге больше, чем дольше система выполняет свою задачу корректно (взбирающийся по лестнице робот получает +1 очко за каждую преодолённую без потери равновесия ступеньку, а если он споткнулся, приз обнуляется, — тогда управляющий им ЦИИ будет стремиться максимизировать именно накопительное поощрение, а не зацикливаться на совершенствовании каждого шага),
- внутренние по отношению к среде обучения награды (собирающая некие предметы в игре модель получает +0,05 балла за каждый — это помогает, с одной стороны, стимулировать накопление ресурсов, а с другой — не выводить эту побочную задачу в приоритет по сравнению с главной, в данном случае с прохождением лабиринта, по которому эти предметы разбросаны),
- внешние по отношению к той же среде награды (чаще всего присуждаются наблюдающим за обучением с подкреплением оператором — можно сравнить с баллами «за артистизм» в фигурном катании: робот просто переместил объект с одного места на другое — нет внешнего подкрепления; сделал это каким-то особенно изящным, на человеческий взгляд, образом — сразу +50 очков),
- специфические подкрепления (полностью зависят от поставленной перед ЦИИ задачи и могут быть весьма разнообразными по степени воздействия на систему; например, если в процессе обучения в виртуальной реальности робот случайно обнаружит программный баг, что позволит ему сразу оказаться на выходе из лабиринта, то призванной решать логические задачи системе логично будет присудить за это крупный штраф, а вот нацеленной на поиск прорех в игровом коде, напротив, — столь же существенное поощрение).
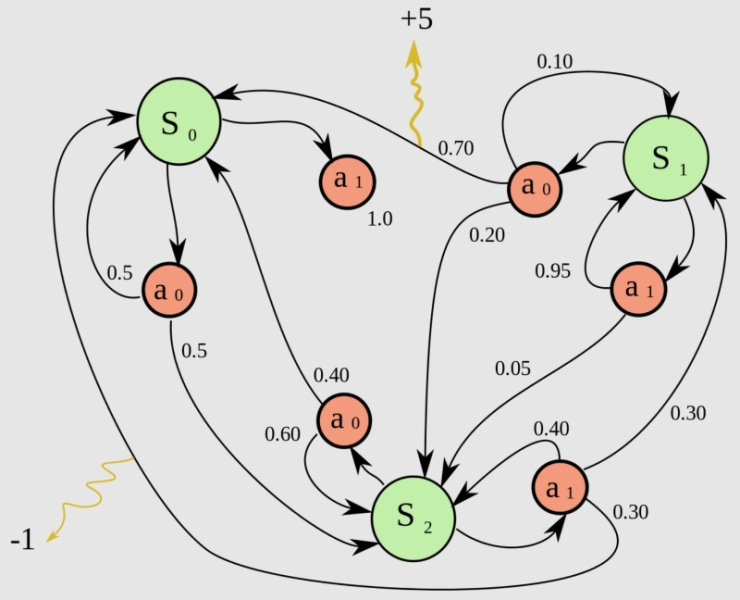
Как следует из приведённых примеров, среда, в которой производится обучение с подкреплением, столь же важна в плане выработки корректной стратегии действия системы, как и сам целеполагающий ИИ. Именно поэтому ЦИИ относят чаще всего к агентам, а не к универсальным генеративным моделям, ведь при изменении условий присуждения наград и поощрений существенно может измениться и сам образ действий искусственного интеллекта. Обсуждавшийся чуть ранее AlphaZero именно потому и оказался способен с равным успехом играть в три различных игры, что доски и правила для всех трёх существенно разные: не факт, что вышло бы натренировать демонстрирующую столь же высокие результаты модель одновременно для игры в классические шашки и, скажем, в поддавки. Важно также подобрать корректное соотношение между различными видами поощрений: если робот после очередного поворота в лабиринте не зашёл в тупик, это заслуживает малой награды, тогда как успешный выход из лабиринта — большой.
Как ни кажется удивительным, но этот несложный в общем-то набор правил поощрения и наказания действительно позволяет ЦИИ формировать успешные стратегии решения тех или иных задач в определённых средах — как помогают базовые реакции на внешние раздражители простейшим организмам, вовсе не имеющим нервных клеток, выживать, размножаться и эволюционировать. При этом — поскольку модель сохраняет возможность менять веса всё время, пока действует, а не использует раз и навсегда затверженную в процессе обучения конфигурацию этих самых весов для инференса — ЦИИ с успехом способны, в отличие от ряда других систем машинного обучения, разрешать «дилемму использования-узнавания» (exploitation-exploration dilemma). Суть её в том, что, однажды обнаружив некий успешный путь решения задачи, интеллектуальный агент — не обязательно компьютерный, кстати, с людьми это тоже случается сплошь и рядом — стремится перестать искать добра от добра и принимается раз за разом использовать (эксплуатировать) этот самый способ. Тогда как и среда вокруг него может динамически меняться, и его собственные способности, потребности, ресурсы могут каким-то образом эволюционировать — неважно; «не сломано — не чини». А когда вдруг нечто важное всё-таки ломается, бывает обычно уже слишком поздно.
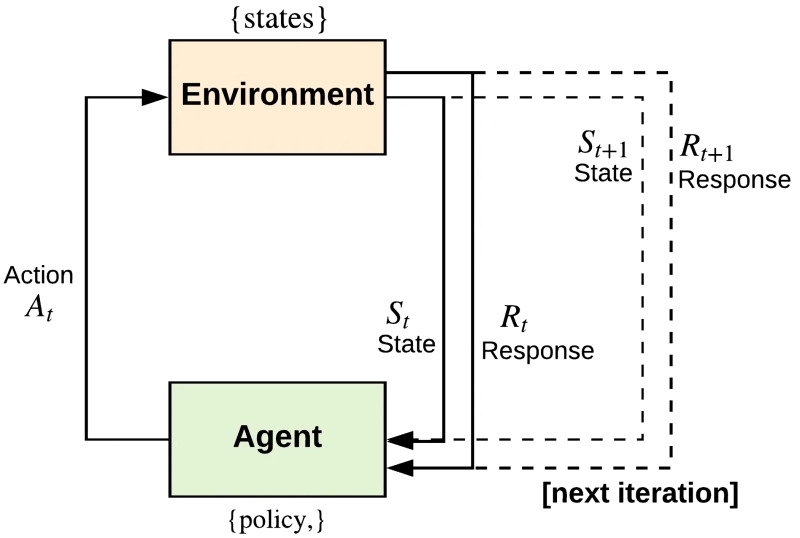
Так вот, ЦИИ не так уж сложно определённым образом «запрограммировать» на регулярное, пусть и ограниченное по глубине, исследование своего уже, казалось бы, изученного прежде, в ходе самотренировки, окружения, — точнее, поставить ему среди прочих целей задачу время от времени такого рода исследования (exploration) проводить. Выбираться, говоря языком психологов, из зоны комфорта, чтобы рассматривать новые возможности (которых может и не появиться, кстати, — вот почему задача узнавания не должна иметь наивысший приоритет, т. е. максимальное подкрепление; если, конечно, речь не идёт о специализированном агенте-исследователе), тестировать их, и если те окажутся подходящими — перестраивать наработанный шаблон действий для выхода на новый оптимум.
Кстати, удачно подобранная для работы ЦИИ-агента среда сама по себе может создавать предпосылки для корректной балансировки использования и узнавания. Всё тот же AlphaZero его разработчики недаром заставляли играть с самим собой: если бы его соперником был определённый человек либо специализированная, не построенная по принципу генеративной нейросети система вроде DeepBlue, максимум, чего он достиг бы, — это уровня своего соперника. Не было бы никаких причин покидать зону комфорта, в которой он и так, условно, более половины партий выигрывает. Противопоставленный же сам себе, ЦИИ-агент с установкой на победу (по сути, выходит, — на победу над самим собой; ницшеанцы беззвучно аплодируют) непрерывно рос и развивался с каждой партией, раздвинув в итоге границы зоны комфорта до установленных самой его аппаратной основой физически достижимых пределов.
Особенно удачным подходом к обучению с подкреплением зарекомендовал себя безмодельный метод Q-learning, предложенный Крисом Уоткинсом (Chris Watkins) ещё в 1989 г. «Безмодельность» (model-free) его заключается как раз в исходном отсутствии у системы «представлений» об устройстве среды, в которой она оперирует, — есть только набор правил, необходимых для действий в этой среде. Человек, рассматривая рисунок лабиринта, видит сразу всю картину и сходу отбрасывает множество заведомо неподходящих вариантов его прохождения, тогда как робот, поставленный в исходную точку пути, не имеет ни малейшего представления о том, где там выход. У управляющего им ЦИИ просто есть инструкция (таблица, содержащая перечень всех возможных подкреплений за все возможные действия), где сказано, что шаг в любом доступном направлении выполняется без штрафа, что уткнуться в стену — значит потерять балл, и что за достижение открытого со всех четырёх сторон участка (собственно выхода) полагается крупная награда. Уже этого достаточно, чтобы агент начал обучаться оптимальному способу действий, просто получая обратную связь от своего окружения, — это то, что называют асинхронным динамическим программированием. Таким образом, Q-обучение представляет собой такое обучение с подкреплением, в ходе которого подбирается оптимальная политика совершения действий для любого конечного марковского процесса принятия решений.
В итоге ИИ-система, обучающаяся с подкреплением, ориентируется на максимизацию суммарной награды, которую в принципе можно получить в ходе исполнения той или иной задачи, учитывая такие тонкости, как штрафы за чрезмерную медлительность, соотношение размеров поощрений за отсутствие явных промахов (мало очков) и сокрушительную победу (сразу много) и т. п. Результат (само)тренировки такого ЦИИ-агента может показаться стороннему наблюдателю едва ли не свидетельством подлинной разумности действующей в оперативной памяти большого компьютера вычислительной модели — точно так же когда-то первые натуралисты отказывались признавать сложные инстинкты животных (самоорганизацию пчелиного улья, ежегодную миграцию птиц и проч.) следствием постепенной адаптации к естественной среде, а не прямым вмешательством всеведущего Творца. Но нет, до сильного ИИ сегодняшним целеполагающим агентам ещё очень далеко — примерно как самоорганизующимся в колонии одноклеточным организмам до качественно более сложных многоклеточных. Впрочем, биологическая эволюция этот скачок всё-таки совершила — значит, есть шанс и для систем искусственного интеллекта, пусть и в отдалённом (пока?) будущем.
Материалы по теме
- Исследователи DeepMind предложили распределённое обучение больших ИИ-моделей, которое может изменить всю индустрию.
- CoreWeave поставит IBM ИИ-суперкомпьютер на базе NVIDIA GB200 NVL72 для обучения моделей Granite.
- Учёные MIT подсмотрели у больших языковых моделей ИИ эффективный метод обучения роботов.
- Нобелевскую премию по физике присудили отцам нейросетей и машинного обучения.
- CoreWeave и Run:ai помогут заказчикам в обучении ИИ.


Добавить комментарий